Hibernate学习2
Hibernate中的持久化类
持久化 : 即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘,数据库)。
在hibernate中一个的java类与数据库建立了映射关系那么就可以称该类为可持久化类。
持久化类的编写规则
- 该类必须有无参构造器 (因hibernate需要使用反射来创建该类对象);
- 持久化类的属性要私有,且对外提供get和set方法;
- 持久化类的属性类型申明尽量使用包装类型 (因为包装类型和基本数据类型的初始化值不同,在某些时候可能会有歧义.例如某个属性表示某人的奖金,使用基本类型double,那么初始化值为0.0d,如果在持久化到数据库时没有赋值,那么数据库中奖金的字段的值就为0,此时这个0就有歧义,究竟是这个人没有奖金呢还是在插入时忘记给奖金赋值了呢?而如果使用包装类Double则不存在此问题,因为包装类的默认值就是null);
- 持久化类要有一个唯一标示OID与映射的表的主键相对应 (因为hibernate需要这个唯一标示OID来区分是否是同一个持久化类);
- 持久化类尽量不要用final来修饰 (因为hibernate使用了延迟加载的机制,这个机制会产生代理对象,hibernate使用字节码的增强技术来生成代理对象,会继承该类,如果使用final修饰,那么该类就不能被继承,那么延迟加载就会失效)
Hibernate主键的生成策略
主键的分类
- 自然主键 : 把具有业务含义的字段作为主键(假如有一个人员表,其中有一个邮箱的字段,使用邮箱作主键,如果后期允许邮箱重复出现,那么就需要重新设计表结构,重新修改源码)
- 代理主键 : 把不具有业务含义的字段作主键(通常使用代理主键)
主键生成策略
- increment :适用于long short int类型的主键,每次hibernate会以(select max(主键字段名) from 表)的形式去该表中找出当前表中最大的主键值,然后+1做为下一主键值,适用于单线程条件下,但是这样在多线程的条件下就是不安全的了,两个线程可能会取到同一个主键的值.
- identity : 采用数据库自身提供的主键生成标示符,前提是数据库支持数据增长数据类型.
- sequence : 采用数据库自身提供的序列生成标示符号,前提是数据库支持序列.
- native : 根据底层数据库对自动生成标示符的能力在identity,sequence,hilo三种生成器中自动选择.
- uuid : hibernate采用128位的uuid的算法来生成标示符,不常用,字符型主键占用更多的空间.
- assigned : 放弃主键生成策略,自己指定主键,适用于自然主键.
Hibernate核心配置文件配置主键生成策略
<hibernate-mapping>
<class name="com.test.hibernate_day3.domain.User" table="sys_user">
<id name="user_id">
<!-- 配置主键生成策略 -->
<generator class="native"></generator>
</id>
<property name="user_code"></property>
<property name="user_name"></property>
<property name="user_password"></property>
<property name="user_state"></property>
</class>
</hibernate-mapping>
Hibernate持久化对象的三种状态
- 瞬时态(Transient) : 即该对象没有唯一OID且该对象没有和Hibernate session关联;
- 持久态(Persistent) : 即该对象有唯一OID且在session的缓存中,session没有关闭且数据库中有该对象;
- 游离态(Detached) : 即该对象与数据库仍存在关联,只是失去了和当前session之间的关联;
三种状态之间的转换
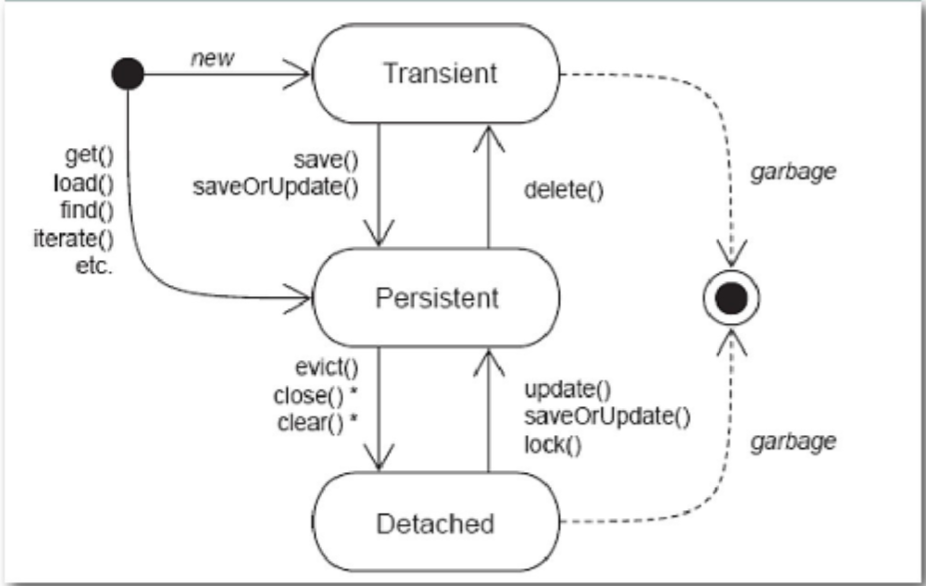
持久态的对象能够自动更新数据库
public void test() {
Session session = HibernateUtils.getSession();
Transaction transaction = session.beginTransaction();
Customer c1 = session.get(Customer.class, 1l);
c1.setCust_name("test");
//此时我不需要调用update方法即可自动更新数据库中该条的信息,这全依赖hibernate的一级缓存
transaction.commit();
}
Hibernate的一级缓存
什么是hibernate的一级缓存
hibernate的一级缓存指的就是Session缓存,Session缓存是一块内存空间,用来存放相互管理的java对象.在使用hibernate查询对象的时候,首先会依据唯一的OID在Session缓存中查找该对象是否存在,如果存在则直接返回使用,如果不存在,再向数据库就行查询,并保存到一级缓存中;一级缓存可以减少对数据库的访问次数。
在Session接口的实现中包含了一系列的Java集合,这些集合构成了Session缓存,只要Session对象的生命周期没有结束,那么存放在其中的缓存数据就不会消失(调用Session的close()等方法会清空缓存),所以一级缓存被称为Session的基本缓存.
一级缓存的结构(快照区snapshot)
Hibernate向一级缓存存放数据的时候会同时拷贝一份存放到快照区,当使用commit()的时候,会清理缓存,并通过IOD将缓存中的数据与快照区的数据进行对比,如果相同,则不进行操作,如果不同,则自动更新数据库,并更新快照区;hibernate快照的作用就是确保一级缓存中的数据与数据库中的数据一致.
Hibernate的事务管理
在hibernate中可以通过代码来操作管理事务;
如Session.beginTransaction() 开启事务, Session.commit()来提交事务, Session.rollback()在出错是回滚事务.
同时还支持在核心配置文件中配置事务的隔离等级;
<!--在hibernate.cfg.xml中的根节点下进行配置-->
<property name="hibernate.connection.isolation">1</property>
<!--
隔离级别表示
Read uncommited isolation --- 1
Read commited isolation --- 2
Repeatable read isolation --- 4
Serializable isolation --- 8
-->
一般对事务的操作都是放在业务层,而开启事务就需要保证Session(也就是JDBC中的Connection)从开启到结束都是同一个,这样这个事务才有效,那么如何保证呢
- 在业务层获取并传给Dao层(不好,破坏了分层,需要将部分Dao层代码写到业务层);
- 通过ThreadLocal将获取到的Session与当前线程绑定,然后在Dao层中通过当前线程获取
第二种为常用的方案,但是在hibernate中我们完全不用写代码操作,只需要配置一下即可;同时hibernate中也提供了三种对Session的管理方式:
- thread 这个就是利用ThreadLocal来实现的,将Session对象的生命周期绑定给本地线程
- jta 将Session对象的生命周期与jta事务绑定
- managed Hibernate委托程序来管理Session对象的生命周期
在配置文件中配置
<property name="hibernate.current_session_context_class">thread</property>